Das Auswahlhandeln im Wissenschaftsjournalismus lässt sich als Ergebnis eines „information overload“ deuten. Dem begegnet der Journalismus durch die Konzentration auf nur wenige Journals. Interpretationsversuche einer sonderbaren Verteilung. VON MARKUS LEHMKUHL
Ich habe zwischenzeitlich mit vielen Kollegen über die sonderbare Verteilung der journalistischen Auswahlentscheidungen gesprochen, über die ich kürzlich hier berichtet habe. Um es kurz zu machen: Die Kollegen teilen mein Erstaunen nur sehr bedingt. Am Schlimmsten fand ich das Feedback eines Kollegen, der diese Verteilung für ganz selbstverständlich hielt. „Ist doch klar, dass das so verteilt ist.“ Er sieht da den Zufall am Werk.
Ich bin – mindestens vorerst – anderer Meinung. So eine Verteilung kommt keinesfalls zufällig zustande. Nochmals zur Erinnerung: Wir haben unter anderem ermittelt, dass auf 100 Journals, die ein einziges öffentlich resonanzstarkes Paper publiziert haben, 28 kommen mit zwei, 10 mit drei usw.. Das, was interessant daran ist, ist folgendes: Die Zahl der Journals nimmt absolut regelmäßig exponentiell ab, der Exponent der Gleichung beträgt 2,2. Das heißt: Auf nur wenige von über 2400 Journals entfällt das Gros der ausgewählten Resultate. Das kann kein Zufall sein!
Aus der Verteilung ist zu schließen, dass wir vor einem Matthäus-Effekt stehen. „Wer hat, dem wird gegeben“. Ein anderer Ausdruck dafür ist „rich-get-richer mechanism“ oder „Yule process“. Wenn wir uns zwei identische Studien vorstellen, von denen eine im Journal of Endocrinology erscheint und die andere in Nature, dann sind die Auswahlchancen des ersten Papers um ein Vielfaches niedriger. Mit anderen Worten: Eine Studie in bereits sehr etablierten Journals wie Science, Nature, JAMA und Co wird überproportional viel Aufmerksamkeit zuteil. Die Verteilung deutet darauf hin, dass wir diesen Matthäus-Effekt relativ genau quantifizieren können, d.h. wir können einen Exponenten angeben für die überproportionale Zuwendung von Interesse seitens des Journalismus.
Studien aus Nature und Co haben nur deshalb eine höhere Chance auf mediale Resonanz, weil sie von diesen Journals ausgewählt wurden
Ich höre schon die Einwände: „Natürlich wird dem Nature Paper deshalb mehr Aufmerksamkeit zuteil, weil es einfach besser und interessanter ist.“ Ein solcher Einwand würde unterstellen, dass Journalisten die Qualität von Studien beurteilen können. Das bestreite ich nicht grundsätzlich. Klar kann man eine Studie mit zehn Probanden von einer mit 10.000 unterscheiden. Was der Einwand aber darüber hinaus unterstellt, ist, dass sich Journalisten deshalb viel öfter für eine Studie in Nature und Co entscheiden, weil sie nach reiflicher Abwägung des sonstigen Angebots die Studien dort einfach besser finden. Das bestreite ich allerdings ganz entschieden.
Die Verteilung deutet darauf, dass Studien von wissenschaftlich ähnlicher oder gleicher Qualität wesentlich bessere Chancen haben, wenn Sie bei Nature, Science, PNAS, JAMA und Co erscheinen, und zwar nicht, weil sie besser oder interessanter sind, sondern nur deshalb, weil sie von diesen Journals ausgewählt wurden. Ob nicht gleichzeitig interessantere oder bessere Studien in anderen Journals erscheinen, zum Beispiel in eLife, kann der Journalismus nicht abschätzen. Erstens, weil er nicht über die notwendige Expertise verfügt, um sehr gut von gut zu unterscheiden (das können, soweit wir wissen, nicht mal die Peers. Helga Nowottny fasste das Dilemma kürzlich in einem Satz zusammen: „It takes excellence to recognize excellence”.) Und zweitens – und das ist der wichtigere Grund -, weil er über kein Instrument verfügt, dass ihm einen Vergleich zwischen einer Unzahl von Studien überhaupt ermöglicht. Selbst wenn es aus journalistischer Sicht unter den etwa zweieinhalb Millionen Studien, die jährlich veröffentlicht werden, bessere gibt als die bei Nature und Co, dann kann sich der Journalismus dessen nicht gewahr werden, weil es einfach zu viele gibt, die er beurteilen müsste.
Die Abhängigkeit des Journalismus von großen Journals ist eine Folge des „information overload“
Mein US-amerikanischer Kollege Vincent Kiernan geißelt seit Jahren das Embargo-System der großen Journals und plädiert für seine Abschaffung. Er geht davon aus, dass es den Journalismus in seiner Unabhängigkeit beschneidet. Er glaubt, das Embargo-System würde den Journalismus abhängig machen von den Auswahlentscheidungen der großen Journals. Ich konnte mit dieser These nie viel anfangen. Jetzt, wo ich vor dieser Verteilung sitze, beginnt sich das ein wenig zu ändern. Wenn 50 Prozent der Medienresonanz auf Paper aus nur 40 von mehr als 2400 Journals entfällt, muss man zumindest Zweifel hegen, dass man vor dem Ergebnis einer unabhängigen Auswahl steht. Allerdings glaube ich nicht, dass das Embargo dafür ursächlich verantwortlich ist. Hauptgrund für die Abhängigkeit des Journalismus von etwa drei Dutzend Journals ist nicht das Embargo, sondern der „information overload“, man könnte den auch „overkill“ nennen, der eine Orientierung an eigentlich ungeeigneten Kriterien nachgerade unausweichlich macht. Das möchte ich versuchen, an Hand eines Beispiels zu illustrieren:
Nehmen wir an, es gibt eine Gruppe von 1000 Lesern, die einen Abenteuerroman lesen wollen. Nehmen wir weiter an, dass Ihnen nur 10 Abenteuerromane zur Auswahl stehen. In so einem Fall können die Leser das gesamte Angebot überschauen und eine unabhängige Wahl treffen. Anzunehmen ist, dass sich in der Verteilung der Käufe Präferenzen der Leserschaft widerspiegeln, zum Beispiel thematische Präferenzen. Es ist aber so gut wie ausgeschlossen, dass sich in einer solchen Konstellation eine sehr starke Ungleichverteilung zeigt, dazu ist die Auswahl zu gering und das Angebot zu ähnlich.
Eine massive Ungleichverteilung des Käuferverhaltens ist aber sehr wahrscheinlich, wenn das Angebot von 10 auf 1000 oder noch mehr Romane anschwillt. In so einem Fall kann keiner der 1000 Leser eine unabhängige Auswahl treffen, weil niemand die Zeit hat, um 1000 oder 10.000 Abenteuerromane vor dem Kauf zu sichten. Die einzelnen Käufer werden ihre Auswahl beschränken, weil die verfügbare Zeit beschränkt ist, sagen wir im Mittel auf 10 Romane. Es wird sich dadurch auf jeden Fall eine Ungleichverteilung beim Kauf ergeben, zum Beispiel deshalb, weil die meisten Menschen zwischen 160 und 180 cm groß sind. Ihr Auswahlhandeln begünstigt allein deshalb Bücher, die auf Augenhöhe im Regal stehen. Es werden also mutmaßlich in diesem Überall von Buchtiteln sehr viel häufiger diejenigen Bücher gekauft, die durch Verkäufer günstig im Regal platziert werden.
Es wird sich über die Zeit eine krasse Ungleichverteilung einstellen. Und diese Ungleichverteilung ist zu einem guten Teil den Verkäufern zuzurechnen, die gelernt haben, was Lesern ganz besonders gefällt und genau das günstig platzieren, so dass sich so eine Ungleichverteilung ergibt, wie wir sie gemessen haben. Mit anderen Worten: Die Ungleichverteilung kommt durch eine Kopplung zwischen Käufern und Verkäufern zustande, wobei der Einfluss des Verkäufers mit anschwellendem Angebot immer weiter zunehmen dürfte, weil er durch sein Handeln bestimmt, was überhaupt ins Auge fällt. Und es kommt darüber hinaus durch die Kopplung der Käufer untereinander zustande, weil die beobachten, was die anderen kaufen.
Immer dann, wenn Sozialsysteme mit Informationen überhäuft werden, entstehen ähnliche Ungleichverteilungen
Ein mathematisches Modell für die Entstehung solcher Verteilungen hat übrigens der amerikanische Physiker und Mathematiker M.E.J. Newman 2005[1] unter Rückgriff auf ein altes Modell von Yule aus dem Jahre 1923 vorgelegt. Es spricht für ein durchaus vitales wissenschaftliches Interesse an diesen Verteilungen, dass der Aufsatz bis jetzt schon über 1000 Mal zitiert wurde. (Journalisten haben das Thema bisher nicht aufgegriffen, soweit ich sehe. Ist etwas schwer verständlich, weil „information overload“ und der ganze „Quatsch-Overload“ im Internet ja rauf und runter thematisiert wird).
Würde man morgen das Embargo-System, EurekAlert und sämtliche anderen Auswahlhilfen abschalten, wäre der Journalismus sicherlich zunächst desorientiert. Bestimmte Journals würden in der Beliebtheit aufsteigen, andere absteigen. Angesichts des Überangebotes an Studien würde sich aber über kurz oder lang wieder eine Verteilung einstellen, die genauso aussieht wie die, die wir gefunden haben.
Das kann ich zwar nicht beweisen, aber ich kann es plausibilisieren. Erstens damit, dass man überall dort, wo man einem „information overload“ begegnet, Verteilungen findet, die der im Journalismus ähneln. Zum Beispiel bei den Verkaufszahlen von Büchern. Oder bei den Clicks auf Websites. Oder bei den Zitierungen wissenschaftlicher Paper. Man findet diese Verteilung aber auch in anderen Bereichen des Journalismus, obwohl die Datenlage hier nicht so rosig ist, was zur Vorsicht mahnt. Patrick Rössler, ein Kommunikationswissenschaftler aus Erfurt, hat sich um die Jahrtausendwende die Auswahl von sieben TV Hauptnachrichtensendungen angesehen. Er hat unter anderem erhoben, wie viele Anlässe an einem Tag exklusiv nur von einer Sendung ausgewählt wurden, wie viele von zwei, wie viele von drei undsoweiter. Wenn man seine Ergebnisse abträgt auf einer logarithmischen Skala, dann liegen die Messergebnisse ziemlich genau auf einer Geraden.
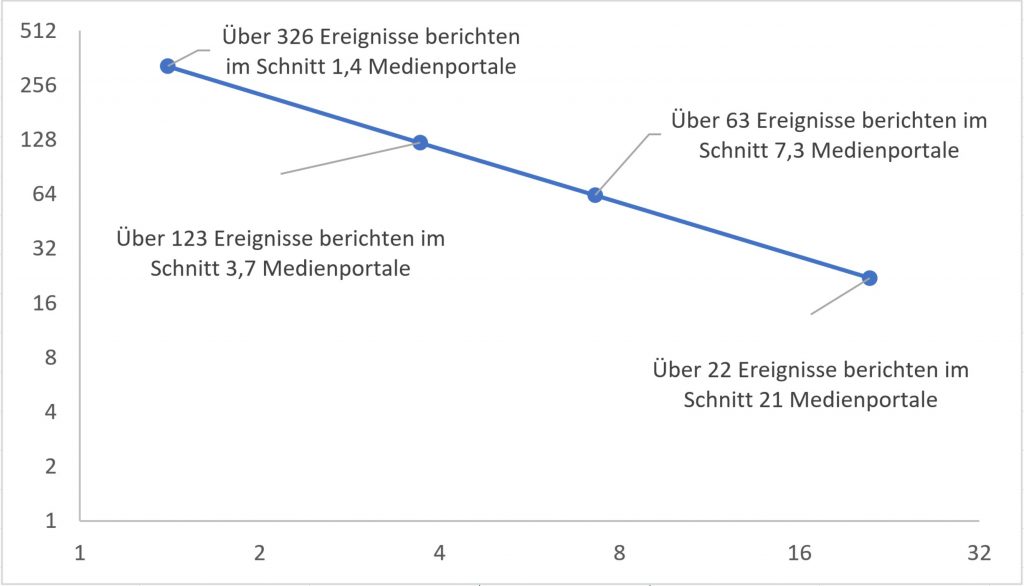
Daten von Veronika Karnowski, LMU München: Anzahl von Ereignissen, die von x Medienportalen gleichzeitig aufgegriffen wurden. Abgetragen auf logarithmischen Skalen. Es zeigt sich wieder eine Gerade.
Gleiches gilt für die Ergebnisse der Münchnerin Veronika Karnowski, die ein Sample aus mehreren tausend Ereignissen, die von reichweitenstarken Online-Portalen aufgegriffen worden sind, unter anderem im Hinblick darauf analysierte, wie viele davon von einem, zwei, drei usw. Portalen gleichzeitig aufgegriffen wurden. Auch hier zeigt sich dieselbe Verteilung. Die meisten Ereignisse werden nur von einem Portal vermeldet, sehr, sehr wenige von allen. Es scheint, dass auch die Auswahl von Front Page-Aufmachern so einer Verteilung folgt, darauf deutet jedenfalls eine Arbeit von Melanie Leidecker-Sandmann hin. Allerdings hat die nur fünf verschiedene Medientitel über jeweils kurze Zeiträume untersucht, da bräuchte man sicherlich bessere Daten, um auf ein Verteilungsmuster schließen zu können.
Der von mir oben zitierte Kollege, der meinen anfänglichen Enthusiasmus so gar nicht teilen wollte, hat – da bin ich sicher – unrecht, wenn er den Zufall am Werke sieht. Dass er nicht weiter erstaunt ist, ist dagegen schon verständlich. Denn die Indizien deuten ja darauf hin, dass solche Verteilungen immer dann entstehen, wenn Sozialsysteme mit Informationen überhäuft werden, es handelt sich vielleicht um so etwas wie „Normalverteilungen im Zeitalter des ‚information overload‘“.
Was wir uns im Moment fragen: Was sagt das aus über die Leistungsfähigkeit des Journalismus? Als ein Argument für seine Unverzichtbarkeit wird ja angeführt, dass er aus dem Unwichtigen das Wichtige aussucht und so Orientierung schafft in diesem Überall, zum Beispiel in den Beiträgen von Alexander Mäder und Franco Zotta hier bei meta. Ist das eigentlich stichhaltig? Darüber machen wir uns Gedanken. Ich halte Sie auf dem Laufenden.
[1] Newman, M. E.J. (2005). Power laws, Pareto distributions and Zipf’s law. Contemporary Physics, 46(5), 323–351.
 Markus Lehmkuhl ist Professor für Wissenschaftskommunikation in digitalen Medien am Karlsruher Institut für Technologie.
Markus Lehmkuhl ist Professor für Wissenschaftskommunikation in digitalen Medien am Karlsruher Institut für Technologie.
Kommentare
Marcus Anhäuser schreibt:
26. Juni 2018 um 06:10 Uhr
Ein Aspekt (neben der PR-Power, die die „führenden Wissenschaftsjournals“ haben), der auch ein Rolle spielen dürfte, aber irgendwie noch gar nicht erwähnt wurde, ist meinem Eindruck nach, dass vor allem Science und Nature eben einen Bauchladen an Themen bedienen. So kann es dann eben passieren, dass, wie zuletzt, die drei meist berichteten Themen laut eurem Newsreel, alle drei aus Nature stammen. (https://www.meta-magazin.org/2018/06/22/foerdern-genscheren-krebs-warum-sterben-die-baobab-baeume-und-wie-schnell-schmilzt-die-antarktis-science-media-newsreel-13-10-06-bis-17-06-2018/#comment-339). Auch die Medizinjournals sind ja innerhalb der Medizin keine auf ein Fach beschränkte Journals. Damit krieg ich eine interessante Mischung aus Themen schon alleine mit diesen Magazinen.
Markus Lehmkuhl schreibt:
27. Juni 2018 um 04:07 Uhr
Ja, da bin ich derselben Ansicht, dass Science, Nature und PNAS multithematisch sind, befördert ganz sicher den Eindruck, dass es sich um quasi Schaufenster der wichtigen und/oder interessanten Ergebnisse handelt, das ist ja Teil dieser Kopplung zwischen Bedürfnissen des Journalismus und denen der Wissenschaft.
Josef König schreibt:
26. Juni 2018 um 10:29 Uhr
Lieber Markus Lehmkuhl,
was mich an diesem Beitrag eher erstaunt, ist dass ein bestimmtes Wort nicht fällt, das aber in der Luft liegt. Aber dieses gehört sowieso zu den Un-Wörtern für Journalisten: „Marketing“! Selbstverständlich haben Nature, Science, PNAS und die anderen wichtigsten Journale ein ausgeklügeltes Marketing-System, ihre Themen an Journalisten heranzuführen – und das Embargo ist nur ein Instrument dafür. Hinzu kommt, dass auch Wissenschaftler ganz genau überlegen, welche Ergebnisse sie in welchem Journal unterbringen können. Und da erweist sich auch der Impact factor der Journale als ein entsprechendes Instrument (für alle Seiten, für die Wissenschaftler wie für die Journalisten) – und so bringt man als Wissenschaftler die besten Ergebnisse in die erstrangigen Journale, die nachrangigen Ergebnisse in die nachrangigen Journale, weil man weiß, dass diese nicht so „wahrgenommen“ werden. Darüber hinaus wirken „Zitationsnetzwerke“ mit, ebenso wie z.B. häufig Nobelpreisträger von den selben Instituten kommen: Es ist ein Zusammenspiel von Qualität UND Netzwerk.
Übrigens ist Marketing natürlich auch ein entsprechendes Instrument der Verleger – auch der Verleger von Romanen, die dann mehr in einen bestimmten Roman investieren, etwa in die Kommunikation und Werbung, in die Ansprache von Rezensenten und natürlich in den Einfluss auf Buchhändler, wo und wie sie bestimmte Romane platzieren sollen.
Und wie diese „platziert“ werden, so werden auch paper von bestimmten Journalen und Wissenschaftlern „platziert“ – z.B. in dem man das Cover für ein Thema „vergibt“ oder auch die Presseinformation dafür besonders verfasst.
Ich sage nicht, dass Journalisten darauf „reinfallen“, aber natürlich ist das eine fast durchgehende „Kaskade“ von der Auswahl des papers im Journal über die Werbung bis hin zur Kommunikation zum „Endverbraucher“. Und so sind auch Journalisten nur Menschen, die sich von der Relevanz von Nature und Science usw. „leiten“ lassen – und haben dann nicht die Zeit oder die Muße auch noch dann die weniger wichtigen Journale hineinzuschauen.
Man kann es auch drastischer sagen: Sie wirken mit daran, dass „Der Teufel immer auf den größten Haufen weiter scheißen kann“ – das gilt auch hier.
Viele Grüße
Josef König
Alexander Mäder schreibt:
27. Juni 2018 um 12:58 Uhr
Nach meinem Eindruck spielt das Embargo-System auch in Deiner Overload-Erklärung eine Rolle: analog zur Platzierung der Romane auf Augenhöhe. Wenn ein Journal groß genug ist, um Mitteilungen mit Sperrfrist zu versenden, wird es für Journalisten interessanter. Wir nutzen dieses Kriterium und den damit verbundenen Service gerne.
Zur Frage, ob es Journalisten gelingt, Orientierung zu schaffen im Übermaß der wissenschaftlichen Publikationen: Ich werbe für einen Journalismus, der sich von dieser Aufgabe löst. Denn neueste Studien tragen zum Wissen der Gesellschaft oft nur wenig bei.
Franco Zotta schreibt:
27. Juni 2018 um 04:06 Uhr
Markus macht mE den Journalismus zu groß und zu klein zugleich. Zu groß, wenn er seine Leistungsfähigkeit daran misst, ob er es schafft, die Paperflut sinnvoll zu filtern. Natürlich nicht – aber das gelingt doch selbst die Wissenschaft nicht (mehr). Zu klein, wenn er insinuiert, wenn der das nicht könne, müsse man sich fragen, ob Journalismus hier dann noch einen Beitrag zur Orientierung leiste. Journalismus ist mE oft ein grobes Schwert, mit dem man im täglich neu zuwuchernden Dickicht Sichtschneisen schlägt. Das ist nicht wenig Orientierung für eine Gesellschaft. Im Gegenteil: Das ist die Bedingung der Möglichkeit von Aufklärung in Zeitgenossenschaft zur akuten Wirklichkeit. Natürlich gleicht das der Quadratur des Kreises, ist also tägliches Scheitern. Nur: Wir haben nichts besseres.